コンテキストの肥大化と
過剰なトークン消費を削減しましょう。
コードの背後にある理由を、必要な瞬間に発現。
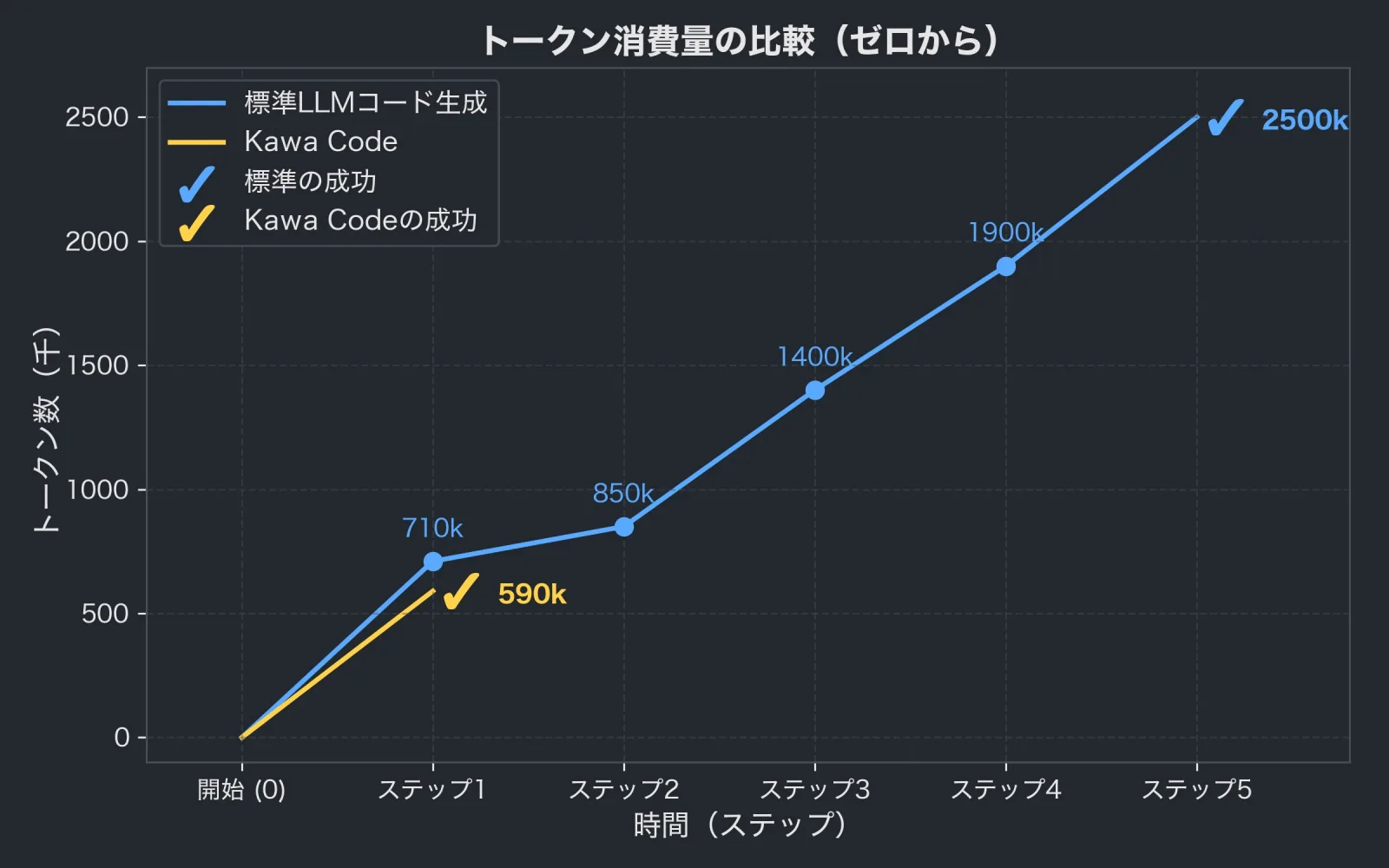
Kawa Codeでは、300万トークンと4時間を要したタスクが、45秒・59万トークンで完了した事例があります。
プロンプトやエージェントから推論された意図と意思決定を自律的に整理し、関連性の高い部分だけを注入することで、手戻り・レビュー負荷・コンテキストの肥大化を削減します。
// 14日間の無料トライアル — クレジットカード不要。
今のAIツールは、コンテキストが多いほど意思決定が良くなると前提しています。その前提は間違っています。
LLMはコンテキストの肥大化により性能が低下します — 関連性が薄れ、矛盾が積み重なり、注意が散漫になり、コストが膨らみます。生物はこの問題をすでに解決しています。どの細胞も、反応の度にゲノム全体を使うわけではありません。
Kawa Codeは逆の賭けに出ます。私たちはキュレートします。私たちは陳腐化した情報を廃止します。必要なものだけを、必要な瞬間にだけ発現させます — 細胞が遺伝子を発現させるように。
Kawa Code = プロジェクトの意思決定ゲノミクス。
人とAIのために設計
人間とAIエージェントが、互いの意思決定と根拠の上に積み重ねていきます。Kawa Codeは、両者の間で推論と連携を運びます。

ソロ開発者
ソロ一人の開発者、多数のAIセッション。Kawa Codeは、AIが効率的に — そして優雅にすら — 作業を進めるために必要な、関連性の高い情報だけを注入します。
- プロンプトとAIのトランスクリプトから、意図とマイクロ意思決定を自動的に抽出します
- オーケストレーション画面で複数エージェントの作業を調整します
- 技術面・ユーザー向けの両面で、最新の機能リストを静かに保ちます
- ゼロ知識システム:APIはあなたのコードを読み取れません
- 英語が母語でなくても大丈夫。Kawa Codeはコードをあなたの母国語に翻訳し、読みやすくします

エンジニアリングチーム
チームチーム全体で意図と意思決定を共有します。
- コンフリクトとコードの交差点が、コミットする前に表面化し、解決されます
- AIの作業による意思決定が、チームの他のメンバー全員にとって即座に関連性の高いコンテキストになります
- 既存プロジェクトでは、
infer historyを実行して、プロジェクトの履歴から意図と意思決定を抽出します - 技術面・ユーザー向けの両面で、最新の機能リストを静かに保ちます
- ゼロ知識システム:APIはあなたのコードを読み取れません — すべての差分は暗号化されます
- AIなしでも利用可能:効率的なトランクベース開発(VS Code、Vim、Emacs、IntelliJの拡張機能)
- 国際チームでは、意図・意思決定・コードを各ユーザーの母国語にAI翻訳します

AIコーディングエージェント
エージェントエージェントは、作業の瞬間に注入される、関連性の高い過去の意思決定だけを受け取ります — コンテキストの肥大化が減り、誤った方向へ進むことも減ります。
- モノレポで作業する複数のエージェント間で、マスターコーディネーターとして機能します
- エージェント間のコンフリクトは高い確信度で解決されるか、あなたの判断を仰ぐために表面化されます — オーケストレーション画面をご覧ください
- 各エージェントはステップごとにKawa Codeと対話し、その作業に関連するコンテキストを引き出します
意思決定ゲノミクスの仕組み
4つの柱が一体となって機能します。「なぜ」をキャプチャし、時間をかけてキュレートし、関連する部分だけをサーフェスし、人間とエージェントをその周りで整合させます。
自動インストルメンテーション
意思決定は、コミュニケーションチャネル、コード、AIとの会話から抽出されます。チームが推論を書き留める必要はありません — システムが、あなたがすでに行っている作業からそれをキャプチャします。
自己剪定するレイヤー
構造化された分類、進化グラフ、廃止処理。意思決定層は、他のあらゆるAIメモリーツールのように単調に蓄積し続けるのではなく、自ら剪定します。
ジャストインタイムのコンテキスト
関連する意思決定が、検索しようと思い立った時ではなく、作業の瞬間に — エージェントのワークフローの中にピン留めされて — 現れます。
コンフリクト&交差点の検出
チーム全体でのコンフリクトと交差点の検出 — 構造的なドリフトやチーム横断の依存関係を、マージ時より前、アーキテクチャの乖離より前にフラグします。
Kawa Codeはあなたの意図と、AIが下すあらゆる小さな意思決定を把握し、
AIには必要なことだけを伝えます。
意思決定ゲノミクスの立ち位置
メモリーツールは記憶を呼び出し、コンテキストツールは情報を注入し、オーケストレーターは動作を調整します。しかし、コードの背後にある推論を構造化し進化させるものはありません — それこそKawa Codeが加えるレイヤーです。
| レイヤー | 機能 | 現在の担い手 |
|---|---|---|
| 長期メモリー/ベクトルメモリー | 過去のテキストを汎用的に呼び出す。 | mem0, Letta, RAG |
| コンテキスト注入 | 保存したコンテキストをそのままプロンプトに渡す。 | Cursor rules, Memory MCP |
| エージェントオーケストレーション | タスク上でエージェントを調整する。 | Agent frameworks |
| 意思決定ゲノミクス | 変更の背後にある推論を構造化し進化させる — 重要なものだけを発現し、人間とエージェントをその周りで整合させる。 | Kawa Code · 欠けているレイヤー |
wikiは記憶します。Kawa Codeはあなたとともに考えます。
効果は出ていますか?
Kawa Codeはバックグラウンドで静かに働きます。価値が出ているかを見分ける方法をご紹介します。
- エージェントが確定した意思決定の再説明を求めなくなります — すでに把握しているからです。
- コンフリクトがマージ前に表面化します。マージ後ではなく、エディタ上で二人の作業がまだ食い違っているうちに気づけます。
- 古いコードに戻る作業が速くなります。意図と意思決定が一緒に戻ってくるからです。
- オーケストレーションパネルが、定型文ではなくチームメイトに読んでほしい意思決定で満たされていきます。
「このセッションでKawa Codeはどう役立ちましたか?どの意図・意思決定・過去のコンテキストを使い、それらがなければ何が難しくなっていましたか?」
大きなタスクの終わりに振り返りの質問を一つするのが、得られている価値を正直に把握する最も簡単な方法です。
Kawa Codeをダウンロード
記憶と共に開発を始めましょう。デスクトップアプリは、Claude Code、Cursor、Windsurf向けのMCPサーバーを同梱しています。